Datasets¶
Base classes¶
-
class
fuel.datasets.base.Dataset(sources=None, axis_labels=None)[source]¶ Bases:
objectA dataset.
Dataset classes implement the interface to a particular dataset. The interface consists of a number of routines to manipulate so called “state” objects, e.g. open, reset and close them.
Parameters: - sources (tuple of strings, optional) – The data sources to load and return by
get_data(). By default all data sources are returned. - axis_labels (dict, optional) – Maps source names to tuples of strings describing axis semantics, one per axis. Defaults to None, i.e. no information is available.
-
sources¶ The sources this dataset will provide when queried for data e.g.
('features',)when querying only the data from MNIST.Type: tuple of strings
-
provides_sources¶ The sources this dataset is able to provide e.g.
('features', 'targets')for MNIST (regardless of which data the data stream actually requests). Any implementation of a dataset should set this attribute on the class (or at least before callingsuper).Type: tuple of strings
-
example_iteration_scheme¶ The iteration scheme the class uses in order to produce a stream of examples.
Type: IterationSchemeorNone
-
default_transformers¶ transformer in the pipeline. Each element is a tuple with three elements:
- the Transformer subclass to apply,
- a list of arguments to pass to the subclass constructor, and
- a dict of keyword arguments to pass to the subclass constructor.
Type: It is expected to be a tuple with one element per
Notes
Datasets should only implement the interface; they are not expected to perform the iteration over the actual data. As such, they are stateless, and can be shared by different parts of the library simultaneously.
-
apply_default_transformers(stream)[source]¶ Applies default transformers to a stream.
Parameters: stream ( AbstractDataStream) – A data stream.
-
close(state)[source]¶ Cleanly close the dataset e.g. close file handles.
Parameters: state (object) – The current state.
-
default_transformers= ()
-
example_iteration_scheme
-
filter_sources(data)[source]¶ Filter the requested sources from those provided by the dataset.
A dataset can be asked to provide only a subset of the sources it can provide (e.g. asking MNIST only for the features, not for the labels). A dataset can choose to use this information to e.g. only load the requested sources into memory. However, in case the performance gain of doing so would be negligible, the dataset can load all the data sources and then use this method to return only those requested.
Parameters: data (tuple of objects) – The data from all the sources i.e. should be of the same length as provides_sources.Returns: A tuple of data matching sources.Return type: tuple Examples
>>> import numpy >>> class Random(Dataset): ... provides_sources = ('features', 'targets') ... def get_data(self, state=None, request=None): ... data = (numpy.random.rand(10), numpy.random.randn(3)) ... return self.filter_sources(data) >>> Random(sources=('targets',)).get_data() # doctest: +SKIP (array([-1.82436737, 0.08265948, 0.63206168]),)
-
get_data(state=None, request=None)[source]¶ Request data from the dataset.
Todo
A way for the dataset to communicate which kind of requests it accepts, and a way to communicate what kind of request is being sent when supporting multiple.
Parameters: - state (object, optional) – The state as returned by the
open()method. The dataset can use this to e.g. interact with files when needed. - request (object, optional) – If supported, the request for a particular part of the data e.g. the number of examples to return, or the indices of a particular minibatch of examples.
Returns: A tuple of data matching the order of
sources.Return type: - state (object, optional) – The state as returned by the
-
next_epoch(state)[source]¶ Switches the dataset state to the next epoch.
The default implementation for this method is to reset the state.
Parameters: state (object) – The current state. Returns: state – The state for the next epoch. Return type: object
-
open()[source]¶ Return the state if the dataset requires one.
Datasets which e.g. read files from disks require open file handlers, and this sort of stateful information should be handled by the data stream.
Returns: state – An object representing the state of a dataset. Return type: object
-
provides_sources= None
-
reset(state)[source]¶ Resets the state.
Parameters: state (object) – The current state. Returns: state – A reset state. Return type: object Notes
The default implementation closes the state and opens a new one. A more efficient implementation (e.g. using
file.seek(0)instead of closing and re-opening the file) can override the default one in derived classes.
-
sources
- sources (tuple of strings, optional) – The data sources to load and return by
-
class
fuel.datasets.base.IndexableDataset(indexables, start=None, stop=None, **kwargs)[source]¶ Bases:
fuel.datasets.base.DatasetCreates a dataset from a set of indexable containers.
Parameters: indexables ( OrderedDictor indexable) – The indexable(s) to provide interface to. This means it must support the syntax`indexable[0]. If anOrderedDictis given, its values should be indexables providing data, and its keys strings that are used as source names. If a single indexable is given, it will be given the sourcedata.Notes
If the indexable data is very large, you might want to consider using the
do_not_pickle_attributes()decorator to make sure the data doesn’t get pickled with the dataset, but gets reloaded/recreated instead.This dataset also uses the source names to create properties that provide easy access to the data.
-
get_data(state=None, request=None)[source]¶ Request data from the dataset.
Todo
A way for the dataset to communicate which kind of requests it accepts, and a way to communicate what kind of request is being sent when supporting multiple.
Parameters: - state (object, optional) – The state as returned by the
open()method. The dataset can use this to e.g. interact with files when needed. - request (object, optional) – If supported, the request for a particular part of the data e.g. the number of examples to return, or the indices of a particular minibatch of examples.
Returns: A tuple of data matching the order of
sources.Return type: - state (object, optional) – The state as returned by the
-
num_examples¶
-
-
class
fuel.datasets.base.IterableDataset(iterables, **kwargs)[source]¶ Bases:
fuel.datasets.base.DatasetCreates a dataset from a set of iterables.
Parameters: iterables ( OrderedDictor iterable) – The iterable(s) to provide interface to. The iterables’ __iter__ method should return a new iterator over the iterable. If anOrderedDictis given, its values should be iterables providing data, and its keys strings that are used as source names. If a single iterable is given, it will be given the sourcedata.Notes
Internally, this method uses picklable iterools’s
_iterfunction, providing picklable alternatives to some iterators such asrange(),tuple(), and evenfile. However, if the iterable returns a different kind of iterator that is not picklable, you might want to consider using thedo_not_pickle_attributes()decorator.To iterate over a container in batches, combine this dataset with the
Batchdata stream.-
example_iteration_scheme= None¶
-
get_data(state=None, request=None)[source]¶ Request data from the dataset.
Todo
A way for the dataset to communicate which kind of requests it accepts, and a way to communicate what kind of request is being sent when supporting multiple.
Parameters: - state (object, optional) – The state as returned by the
open()method. The dataset can use this to e.g. interact with files when needed. - request (object, optional) – If supported, the request for a particular part of the data e.g. the number of examples to return, or the indices of a particular minibatch of examples.
Returns: A tuple of data matching the order of
sources.Return type: - state (object, optional) – The state as returned by the
-
num_examples¶
-
Adult¶
One Billion Word¶
-
class
fuel.datasets.billion.OneBillionWord(which_set, which_partitions, dictionary, **kwargs)[source]¶ Bases:
fuel.datasets.text.TextFileGoogle’s One Billion Word benchmark.
This monolingual corpus contains 829,250,940 tokens (including sentence boundary markers). The data is split into 100 partitions, one of which is the held-out set. This held-out set is further divided into 50 partitions. More information about the dataset can be found in [CMSG14].
[CSMG14] Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, and Thorsten Brants, One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling, arXiv:1312.3005 [cs.CL] <http://arxiv.org/abs/1312.3005>. Parameters: - which_set ('training' or 'heldout') – Which dataset to load.
- which_partitions (list of ints) – For the training set, valid values must lie in [1, 99]. For the heldout set they must be in [0, 49].
- vocabulary (dict) – A dictionary mapping tokens to integers. This dictionary is
expected to contain the tokens
<S>,</S>and<UNK>, representing “start of sentence”, “end of sentence”, and “out-of-vocabulary” (OoV). The latter will be used whenever a token cannot be found in the vocabulary. - preprocess (function, optional) – A function that takes a string (a sentence including new line) as
an input and returns a modified string. A useful function to pass
could be
str.lower.
:param See
TextFilefor remaining keyword arguments.:
CalTech 101 Silhouettes¶
-
class
fuel.datasets.caltech101_silhouettes.CalTech101Silhouettes(which_sets, size=28, load_in_memory=True, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetCalTech 101 Silhouettes dataset.
This dataset provides the split1 train/validation/test split of the CalTech101 Silhouette dataset prepared by Benjamin M. Marlin [MARLIN].
This class provides both the 16x16 and the 28x28 pixel sized version. The 16x16 version contains 4082 examples in the training set, 2257 examples in the validation set and 2302 examples in the test set. The 28x28 version contains 4100, 2264 and 2307 examples in the train, valid and test set.
Parameters: - which_sets (tuple of str) – Which split to load. Valid values are ‘train’, ‘valid’ and ‘test’.
- size ({16, 28}) – Either 16 or 28 to select the 16x16 or 28x28 pixels version of the dataset (default: 28).
-
data_path¶
Binarized MNIST¶
-
class
fuel.datasets.binarized_mnist.BinarizedMNIST(which_sets, load_in_memory=True, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetBinarized, unlabeled MNIST dataset.
MNIST (Mixed National Institute of Standards and Technology) [LBBH] is a database of handwritten digits. It is one of the most famous datasets in machine learning and consists of 60,000 training images and 10,000 testing images. The images are grayscale and 28 x 28 pixels large.
This particular version of the dataset is the one used in R. Salakhutdinov’s DBN paper [DBN] as well as the VAE and NADE papers, and is accessible through Hugo Larochelle’s public website [HUGO].
The training set has further been split into a training and a validation set. All examples were binarized by sampling from a binomial distribution defined by the pixel values.
[LBBH] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE, November 1998, 86(11):2278-2324. Parameters: which_sets (tuple of str) – Which split to load. Valid values are ‘train’, ‘valid’ and ‘test’, corresponding to the training set (50,000 examples), the validation set (10,000 samples) and the test set (10,000 examples). -
filename= 'binarized_mnist.hdf5'¶
-
CIFAR100¶
-
class
fuel.datasets.cifar100.CIFAR100(which_sets, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetThe CIFAR100 dataset of natural images.
This dataset is a labeled subset of the
80 million tiny imagesdataset [TINY]. It consists of 60,000 32 x 32 colour images labelled into 100 fine-grained classes and 20 super-classes. There are 600 images per fine-grained class. There are 50,000 training images and 10,000 test images [CIFAR100].The dataset contains three sources: - features: the images themselves, - coarse_labels: the superclasses 1-20, - fine_labels: the fine-grained classes 1-100.
[TINY] Antonio Torralba, Rob Fergus and William T. Freeman, 80 million tiny images: a large dataset for non-parametric object and scene recognition, Pattern Analysis and Machine Intelligence, IEEE Transactions on 30.11 (2008): 1958-1970. [CIFAR100] Alex Krizhevsky, Learning Multiple Layers of Features from Tiny Images, technical report, 2009. Parameters: which_sets (tuple of str) – Which split to load. Valid values are ‘train’ and ‘test’, corresponding to the training set (50,000 examples) and the test set (10,000 examples). Note that CIFAR100 does not have a validation set; usually you will create your own training/validation split using the subset argument. -
default_transformers= ((<class 'fuel.transformers.ScaleAndShift'>, [0.00392156862745098, 0], {'which_sources': ('features',)}), (<class 'fuel.transformers.Cast'>, ['floatX'], {'which_sources': ('features',)}))¶
-
filename= 'cifar100.hdf5'¶
-
CIFAR10¶
-
class
fuel.datasets.cifar10.CIFAR10(which_sets, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetThe CIFAR10 dataset of natural images.
This dataset is a labeled subset of the
80 million tiny imagesdataset [TINY]. It consists of 60,000 32 x 32 colour images in 10 classes, with 6,000 images per class. There are 50,000 training images and 10,000 test images [CIFAR10].[CIFAR10] Alex Krizhevsky, Learning Multiple Layers of Features from Tiny Images, technical report, 2009. Parameters: which_sets (tuple of str) – Which split to load. Valid values are ‘train’ and ‘test’, corresponding to the training set (50,000 examples) and the test set (10,000 examples). Note that CIFAR10 does not have a validation set; usually you will create your own training/validation split using the subset argument. -
default_transformers= ((<class 'fuel.transformers.ScaleAndShift'>, [0.00392156862745098, 0], {'which_sources': ('features',)}), (<class 'fuel.transformers.Cast'>, ['floatX'], {'which_sources': ('features',)}))¶
-
filename= 'cifar10.hdf5'¶
-
IRIS¶
-
class
fuel.datasets.iris.Iris(which_sets, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetIris dataset.
Iris [IRIS] is a simple pattern recognition dataset, which consist of 3 classes of 50 examples each having 4 real-valued features each, where each class refers to a type of iris plant. It is accessible through the UCI Machine Learning repository [UCIIRIS].
[IRIS] Ronald A. Fisher, The use of multiple measurements in taxonomic problems, Annual Eugenics, 7, Part II, 179-188, September 1936. [UCIIRIS] https://archive.ics.uci.edu/ml/datasets/Iris Parameters: which_sets (tuple of str) – Which split to load. Valid value is ‘all’ corresponding to 150 examples. -
filename= 'iris.hdf5'¶
-
MNIST¶
-
class
fuel.datasets.mnist.MNIST(which_sets, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetMNIST dataset.
MNIST (Mixed National Institute of Standards and Technology) [LBBH] is a database of handwritten digits. It is one of the most famous datasets in machine learning and consists of 60,000 training images and 10,000 testing images. The images are grayscale and 28 x 28 pixels large. It is accessible through Yann LeCun’s website [LECUN].
[LECUN] http://yann.lecun.com/exdb/mnist/ Parameters: which_sets (tuple of str) – Which split to load. Valid values are ‘train’ and ‘test’, corresponding to the training set (60,000 examples) and the test set (10,000 examples). -
default_transformers= ((<class 'fuel.transformers.ScaleAndShift'>, [0.00392156862745098, 0], {'which_sources': ('features',)}), (<class 'fuel.transformers.Cast'>, ['floatX'], {'which_sources': ('features',)}))¶
-
filename= 'mnist.hdf5'¶
-
SVHN¶
-
class
fuel.datasets.svhn.SVHN(which_format, which_sets, **kwargs)[source]¶ Bases:
fuel.datasets.hdf5.H5PYDatasetThe Street View House Numbers (SVHN) dataset.
SVHN [SVHN] is a real-world image dataset for developing machine learning and object recognition algorithms with minimal requirement on data preprocessing and formatting. It can be seen as similar in flavor to MNIST [LBBH] (e.g., the images are of small cropped digits), but incorporates an order of magnitude more labeled data (over 600,000 digit images) and comes from a significantly harder, unsolved, real world problem (recognizing digits and numbers in natural scene images). SVHN is obtained from house numbers in Google Street View images.
Parameters: - which_format ({1, 2}) – SVHN format 1 contains the full numbers, whereas SVHN format 2 contains cropped digits.
- which_sets (tuple of str) – Which split to load. Valid values are ‘train’, ‘test’ and ‘extra’, corresponding to the training set (73,257 examples), the test set (26,032 examples) and the extra set (531,131 examples). Note that SVHN does not have a validation set; usually you will create your own training/validation split using the subset argument.
-
default_transformers= ((<class 'fuel.transformers.ScaleAndShift'>, [0.00392156862745098, 0], {'which_sources': ('features',)}), (<class 'fuel.transformers.Cast'>, ['floatX'], {'which_sources': ('features',)}))¶
-
filename¶
Text-based datasets¶
-
class
fuel.datasets.text.TextFile(files, dictionary, bos_token='<S>', eos_token='</S>', unk_token='<UNK>', level='word', preprocess=None, encoding=None)[source]¶ Bases:
fuel.datasets.base.DatasetReads text files and numberizes them given a dictionary.
Parameters: - files (list of str) – The names of the files in order which they should be read. Each file is expected to have a sentence per line. If the filename ends with .gz it will be opened using gzip. Note however that gzip file handles aren’t picklable on legacy Python.
- dictionary (str or dict) – Either the path to a Pickled dictionary mapping tokens to integers, or the dictionary itself. At the very least this dictionary must map the unknown word-token to an integer.
- bos_token (str or None, optional) – The beginning-of-sentence (BOS) token in the dictionary that
denotes the beginning of a sentence. Is
<S>by default. If passedNoneno beginning of sentence markers will be added. - eos_token (str or None, optional) – The end-of-sentence (EOS) token is
</S>by default, seebos_taken. - unk_token (str, optional) – The token in the dictionary to fall back on when a token could not
be found in the dictionary.
<UNK>by default. PassNoneif the dataset doesn’t contain any out-of-vocabulary words/characters (the data request is going to crash if meets an unknown symbol). - level ('word' or 'character', optional) – If ‘word’ the dictionary is expected to contain full words. The sentences in the text file will be split at the spaces, and each word replaced with its number as given by the dictionary, resulting in each example being a single list of numbers. If ‘character’ the dictionary is expected to contain single letters as keys. A single example will be a list of character numbers, starting with the first non-whitespace character and finishing with the last one. The default is ‘word’.
- preprocess (function, optional) – A function which takes a sentence (string) as an input and returns
a modified string. For example
str.lowerin order to lowercase the sentence before numberizing. - encoding (str, optional) – The encoding to use to read the file. Defaults to
None. Use UTF-8 if the dictionary you pass contains UTF-8 characters, but note that this makes the dataset unpicklable on legacy Python.
Examples
>>> with open('sentences.txt', 'w') as f: ... _ = f.write("This is a sentence\n") ... _ = f.write("This another one") >>> dictionary = {'<UNK>': 0, '</S>': 1, 'this': 2, 'a': 3, 'one': 4} >>> def lower(s): ... return s.lower() >>> text_data = TextFile(files=['sentences.txt'], ... dictionary=dictionary, bos_token=None, ... preprocess=lower) >>> from fuel.streams import DataStream >>> for data in DataStream(text_data).get_epoch_iterator(): ... print(data) ([2, 0, 3, 0, 1],) ([2, 0, 4, 1],) >>> full_dictionary = {'this': 0, 'a': 3, 'is': 4, 'sentence': 5, ... 'another': 6, 'one': 7} >>> text_data = TextFile(files=['sentences.txt'], ... dictionary=full_dictionary, bos_token=None, ... eos_token=None, unk_token=None, ... preprocess=lower) >>> for data in DataStream(text_data).get_epoch_iterator(): ... print(data) ([0, 4, 3, 5],) ([0, 6, 7],)
-
example_iteration_scheme= None¶
-
get_data(state=None, request=None)[source]¶ Request data from the dataset.
Todo
A way for the dataset to communicate which kind of requests it accepts, and a way to communicate what kind of request is being sent when supporting multiple.
Parameters: - state (object, optional) – The state as returned by the
open()method. The dataset can use this to e.g. interact with files when needed. - request (object, optional) – If supported, the request for a particular part of the data e.g. the number of examples to return, or the indices of a particular minibatch of examples.
Returns: A tuple of data matching the order of
sources.Return type: - state (object, optional) – The state as returned by the
-
open()[source]¶ Return the state if the dataset requires one.
Datasets which e.g. read files from disks require open file handlers, and this sort of stateful information should be handled by the data stream.
Returns: state – An object representing the state of a dataset. Return type: object
-
provides_sources= ('features',)¶
Toy datasets¶
-
class
fuel.datasets.toy.Spiral(num_examples=1000, classes=1, cycles=1.0, noise=0.0, **kwargs)[source]¶ Bases:
fuel.datasets.base.IndexableDatasetToy dataset containing points sampled from spirals on a 2d plane.
The dataset contains 3 sources:
- features – the (x, y) position of the datapoints
- position – the relative position on the spiral arm
- label – the class labels (spiral arm)
(Source code, png, hires.png, pdf)
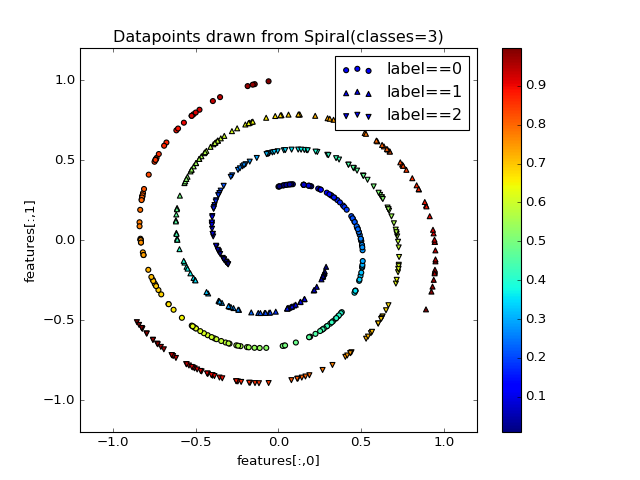
Parameters:
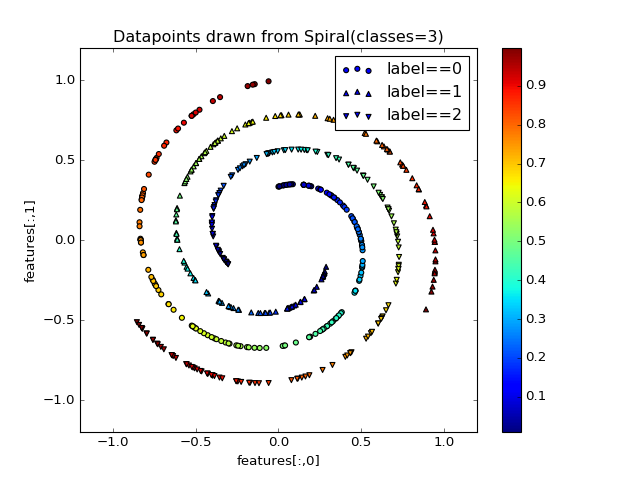{kind=link}
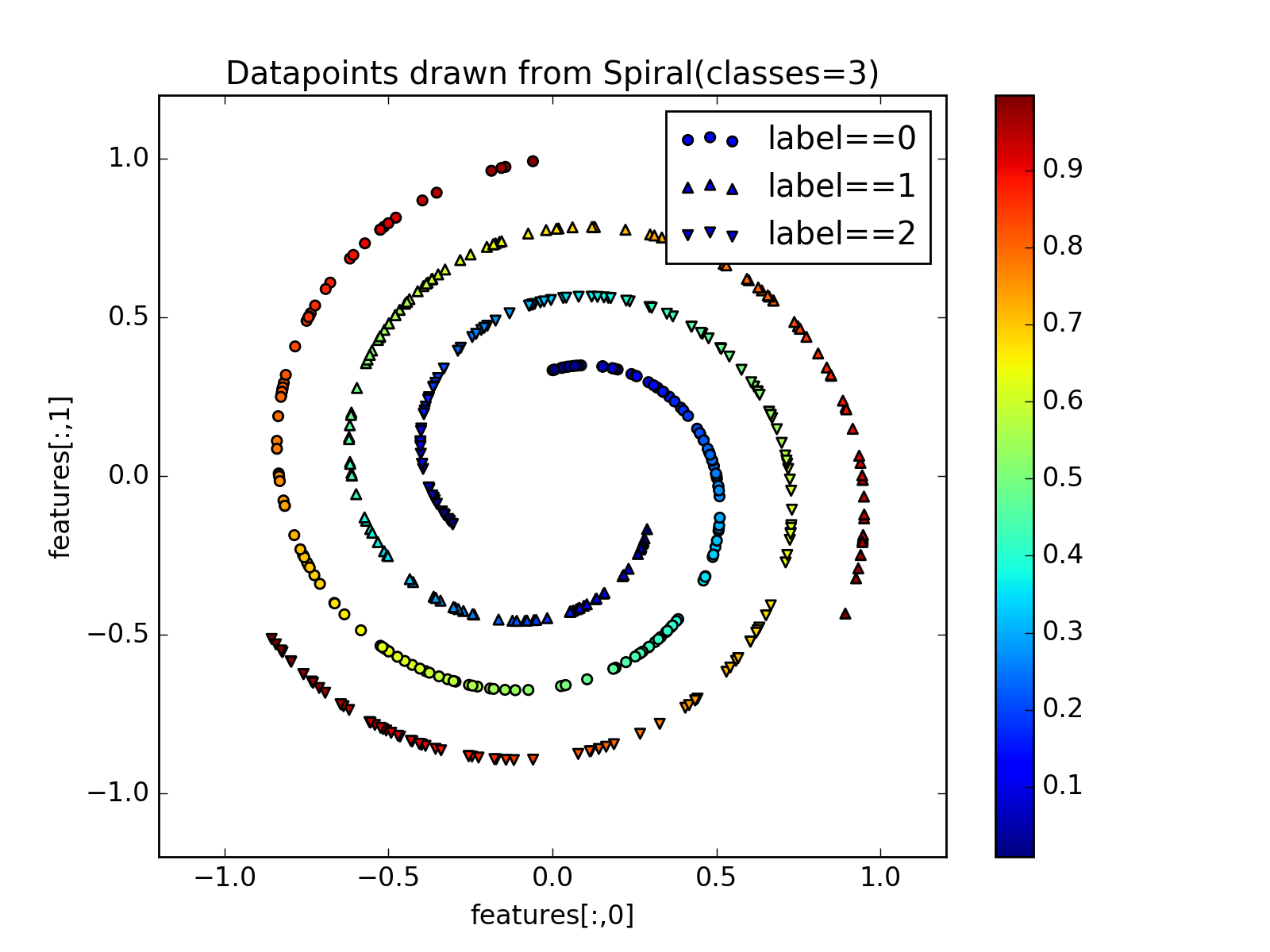{kind=link}
-
class
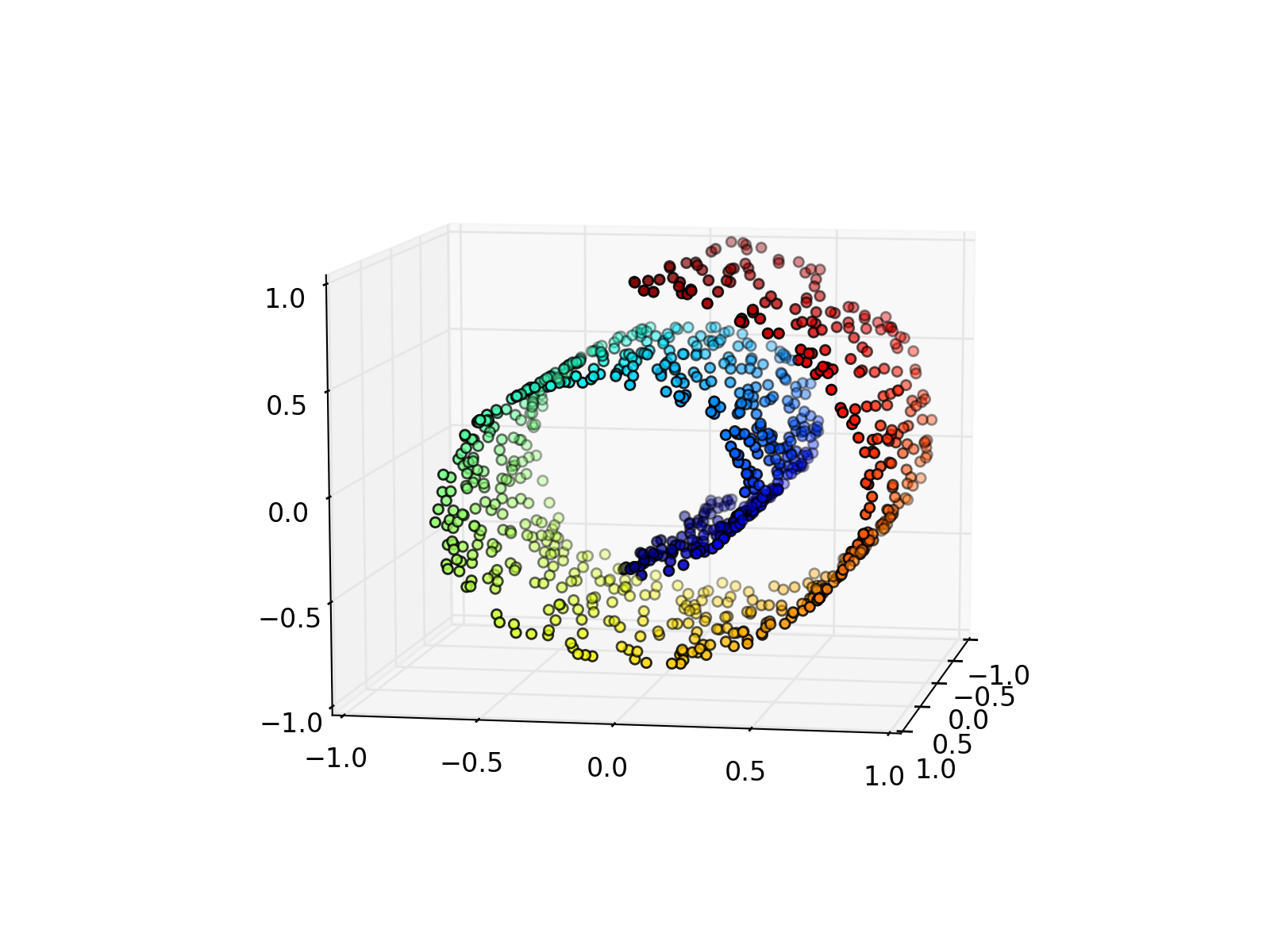
fuel.datasets.toy.SwissRoll(num_examples=1000, noise=0.0, **kwargs)[source]¶ Bases:
fuel.datasets.base.IndexableDatasetDataset containing points from a 3-dimensional Swiss roll.
The dataset contains 2 sources:
- features – the x, y and z position of the datapoints
- position – radial and z position on the manifold
(Source code, png, hires.png, pdf)
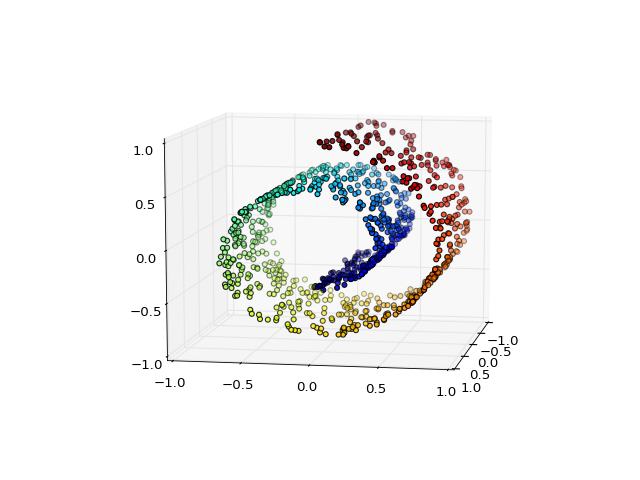
Parameters:
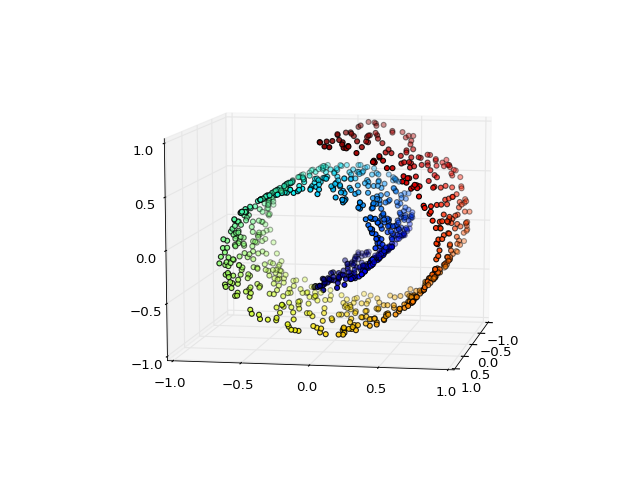{kind=link}
{kind=link}